












REALM-DiT:可控多模态遥感生成(ICML 在投)


项目背景与目标
在杭州滨江区块链与数据安全研究院科研实习期间,我负责并推进了 2.5D 遥感沙盘多模态生成相关工作。项目目标是突破传统遥感生成“只会生成 RGB、缺少几何语义一致性”的瓶颈,实现同一框架下的可控多模态联合生成。
具体希望同时生成并严格对齐:
- RGB 遥感图像
- DEM(高程)
- Land-cover(地表覆盖语义)
这项工作核心不只是“看起来像”,而是“纹理-几何-语义一致且可控”。
我的职责
- 参与 RS3DBench 的多模态数据扩展与训练样本组织
- 参与 GSM-VAE 统一潜空间对齐方案设计与实验
- 参与 REALM 区域可控机制设计(不改动主干架构前提下增强可控性)
- 跑通训练、对比实验与结果分析,整理可复现实验流程
现有的问题
- 现在的遥感生成方法大多只关注 RGB 视觉质量,生成的图像虽然好看,但地形逻辑往往不对,无法用于后续分析和仿真,不能做到可控。
- 多模态训练中,RGB、DEM、Land-cover 之间的无法对齐和噪声问题严重,导致生成的 DEM 和 Land-cover 与 RGB 不一致,缺乏物理和语义上的统一。
我们的动机
- 为了让生成的多种模态对齐,我们必须训练一个5通道VAE,让它从同一个潜空间变量中解码出RGB、DEM、Land-cover三种模态。这样才能保证它们在结构和语义上保持一致。
- 但是如果直接随机初始化训练得到 5通道VAE,虽然重建质量不错,但交给DiT模型生成时会出噪声。
- 我们尝试了多种方法例如只输入RGB,解码出DEM和Land-cover,虽然能生成,但由于只输入了RGB,因此导致DEM和Land-cover质量不稳定;又比如使用谷歌的Orchid vae的distill loss,但是它在DiT上失效了。
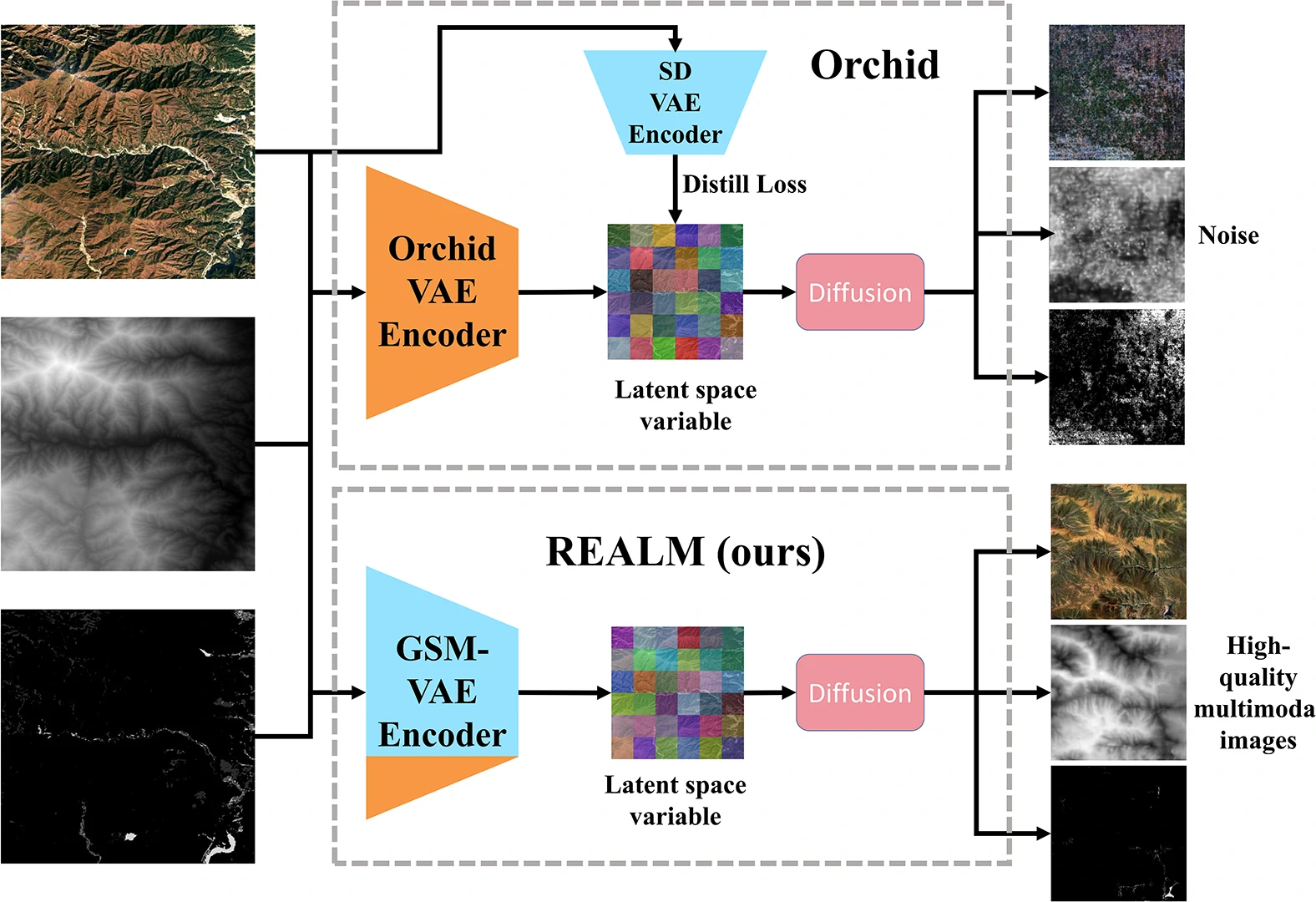
- 因此我们设计了 GSM-VAE,通过冻结原始权重的Encoder+仅训练新加的通道的Encoder+原始的Decoder全部启用训练。这样的方式既让模型拥有了DEM和Land-cover的信息输入,又保持了潜空间分布一致性,最终在DiT上生成的RGB、DEM、Land-cover三者都具有较好的质量和一致性。
方法核心
先从整体流程看,这个框架分为数据与提示词构建、统一潜空间建模、区域可控生成三部分。
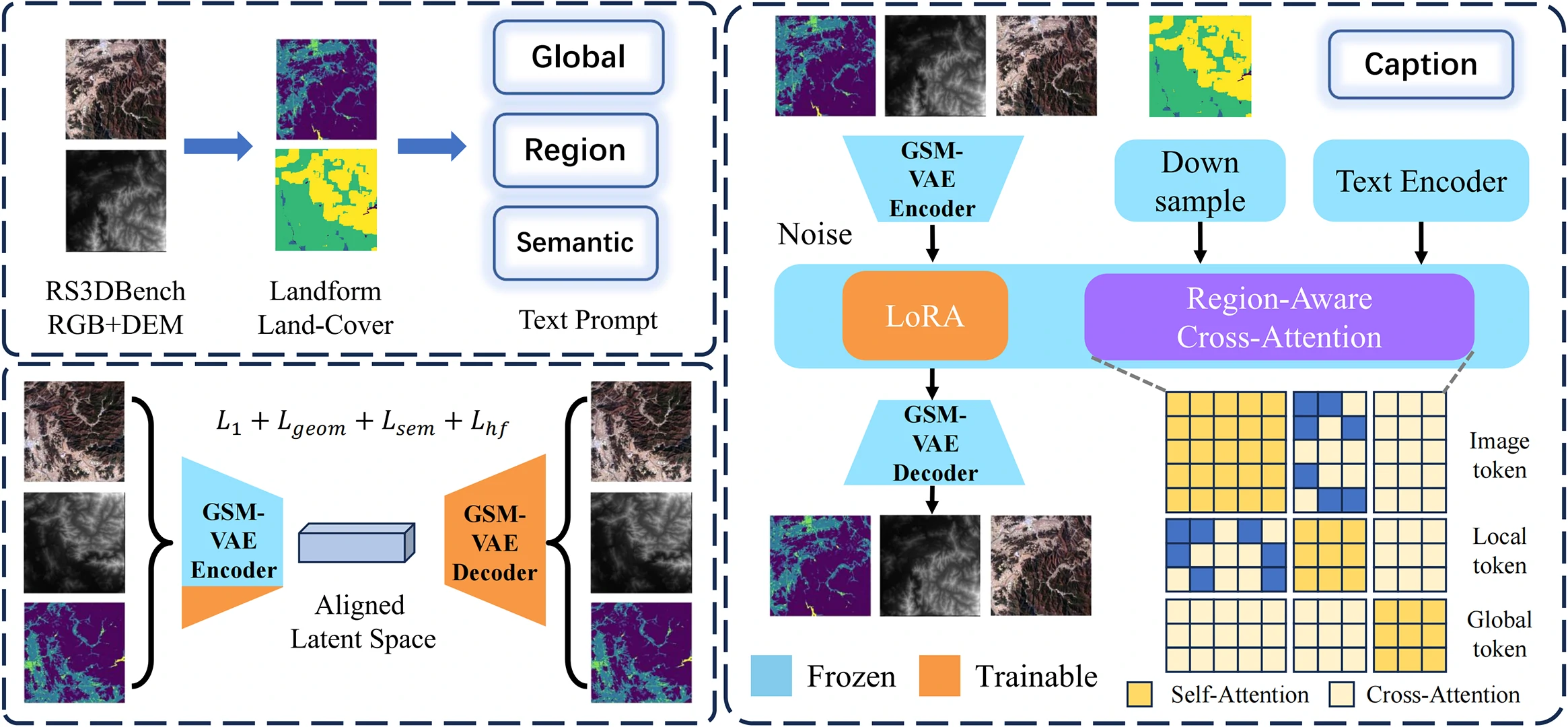
1)数据扩展与分层提示词
将样本组织为像素对齐四元组(RGB / DEM / Land-cover / Landform),并构建分层文本提示词(全局、区域、地形级别细粒度)用于可控训练。
2)GSM-VAE 统一潜空间
通过统一编码器将异构模态投影到拓扑一致的潜空间,减少多模态训练中的结构错位与噪声扩散,增强 DEM 与语义布局的一致性。
3)REALM 区域控制
通过 attention log-bias 方式注入区域约束,实现“局部可控 + 全局语义一致”的统一生成,不依赖对主干网络的大规模改造。
结果与产出
- 多模态重建指标上显著优于主流基线
- 多模态重建保真中深度准确率达到 99.28%
- 对应成果形成 ICML 在投一作论文
实验表格结果
为了更直观说明方法有效性,这里展示两组核心表格实验:
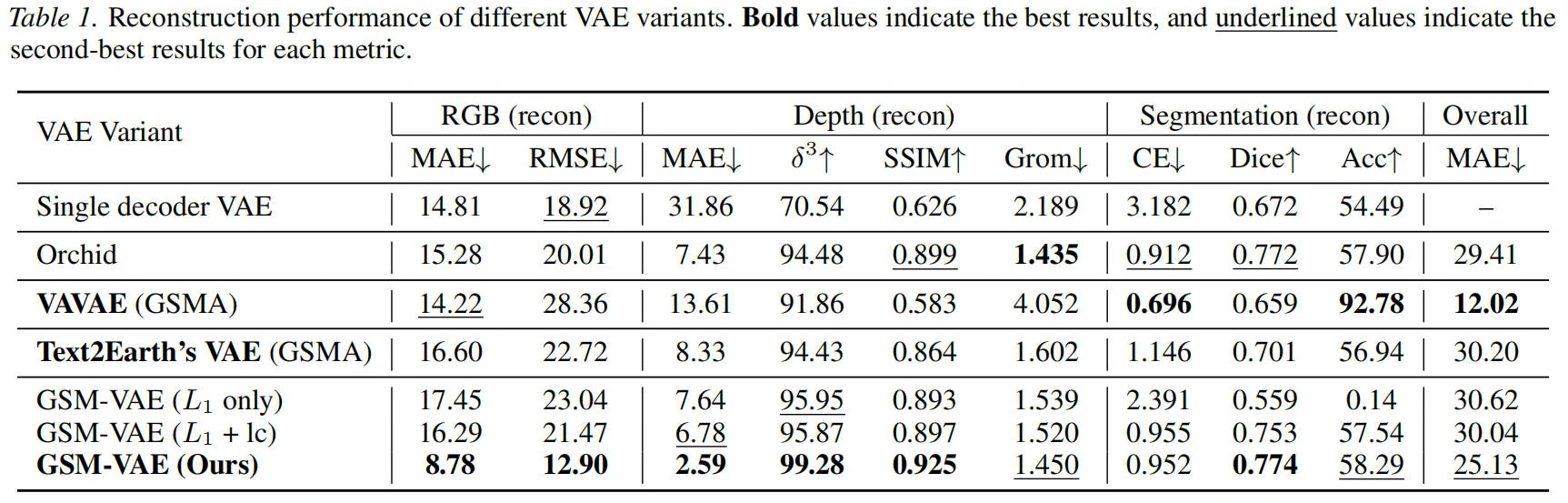
1)VAE 重建结果表格
这组结果主要验证 统一潜空间(GSM-VAE) 是否真的提升了跨模态重建质量。可以看到在 RGB、DEM、Land-cover 的联合重建上,结构一致性与细节保真都更稳定,说明“先对齐潜空间再做生成”是有效的。
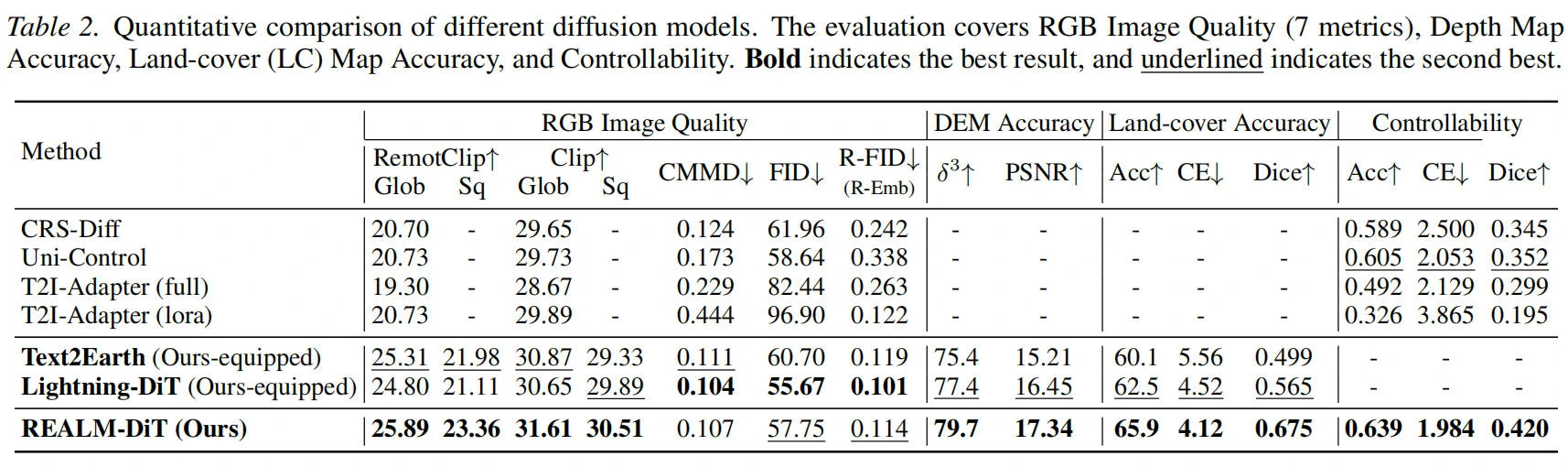
2)REALM 可控生成对比结果表格
这组结果主要验证 区域可控机制(REALM) 的效果。和基线相比,加入区域约束后,局部控制能力与全局语义一致性同时提升,说明模型不仅能“生成出来”,还能“按指定区域稳定生成”。
我的个人价值
- 能在“算法设计-训练评测-结果分析”三段式中独立推进
- 能把研究问题拆解成可落地模块并持续迭代
- 对模型可控性与物理一致性有较强问题意识,能针对性设计方案并解决问题
为了保证“不同模态之间同位对齐”,我们重点检查了 RGB、DEM、Land-cover 三者的一致性。
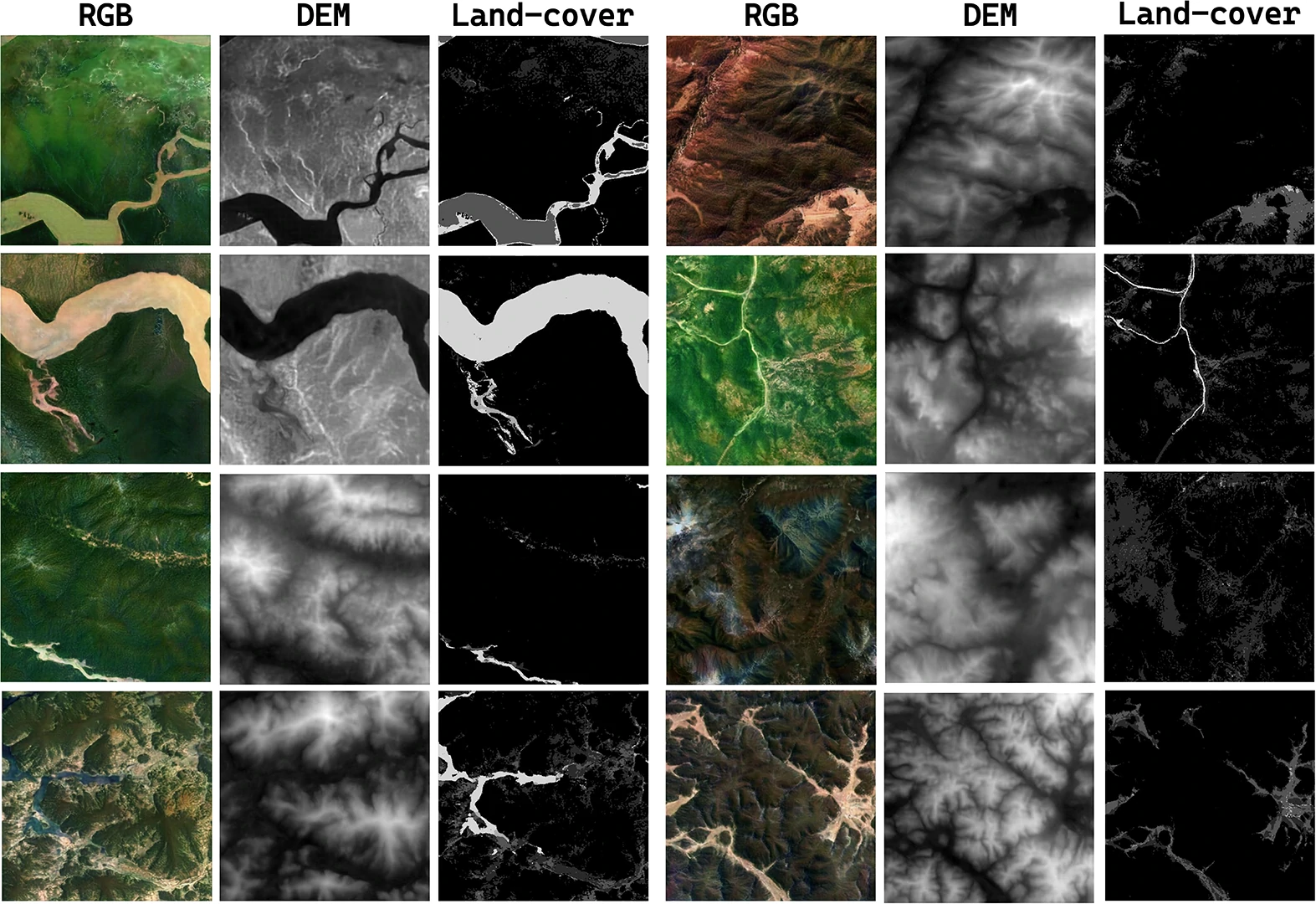
最后是和 baseline 的可控生成对比,能看到在区域控制和整体语义一致性上都有提升。

文章分享
如果这篇文章对你有帮助,欢迎分享给更多人!
部分内容可能已过时